


Initially, Linux-HA will support multi-tailed SCSI attachments. One or more external storage boxes will be attached to two or more nodes.
This requires a new piece of hardware that currently doesn't exist in the mass PC market: a Y cable which attaches to the SCSI adapter in a node (see diagram) and allows for external bus termination. If internal SCSI termination is used on the adapter, an adapter or power outage will also disable the active termination on this adapter. The remainder of the SCSI installation will at best react unpredictably. The Y cable either attaches the bus terminator resistor pack or another SCSI F/W/D cable leading to the next node. The ends of the bus need to be terminated. A simple example is shown below, featuring 2 cluster nodes and 2 external disks or disk boxes.
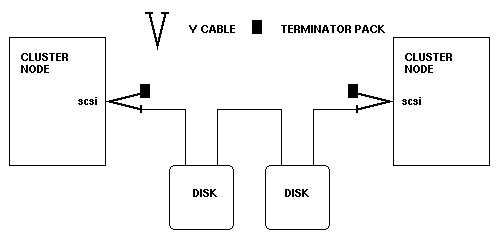
Since the nodes need not be at the end of the SCSI chain, a symmetrical Y cable is needed which can attach either 2 cables or one cable and one terminator pack.
Only differential SCSI will be supported, the reason being the lack of stability of long single-ended cables caused by electrical crosstalk. Ideally, you will want to use Ultra or fast/wide/differential SCSI buses. Single-ended Ultra SCSI (and probably all potential upcoming parallel SCSI technologies with even higher transfer rates) is sort of unusable for multi-host attachments due to cable length restrictions.
Due to the limitations in the ANSI SCSI standard, the maximum bus length for Fast and Ultra wide/differential SCSI is 25 meters except if you use fiberoptic or other bus extenders. This has to be evaluated.
If you use SCSI, please make sure you use multiple adapters in a node, multiple buses and multiple external storage devices (potentially with disk mirroring). Otherwise, an adapter or cable outage will cause a node failover.
In multi-host attachments, make sure the adapter SCSI IDs are all different.
For BusLogic (or Adaptec), the SCSI ID can be set from AutoSCSI (or SCSI-Select), the configuration utilities that are available by typing Ctrl-B (or Ctrl-A) during the host adapter's BIOS initialization. The Host Adapter SCSI ID is stored in nonvolatile memory along with the other configurable parameters. (Leonard Zubkoff) The same is the case with the Symbios Logic 8751D card -- the SCSI ID can be changed from the ROM configuration utility (type Ctrl-C during boot) and is stored in the NVRAM.
On a W/D SCSI bus, there are only 16 usable SCSI addresses. This limits the number of devices that can be attached. External RAID boxes are probably the best bet. Make sure these boxes are designed with redundancy, that is multiple power supplies etc. Some RAID boxes are "host-based", which means they need device drivers on the host they are attached to.
When it comes to adapters, only a subset of the adapters supported by the standard Linux kernel will be supported by Linux-HA, the reason being the need for standardized error messages for certain HA relevant situations (e.g. SCSI adapter permanent failure, disk intermittent error etc.). Authors of other device drivers are invited to join in and re-write their error reporting code. This should be coordinated by the Linux SCSI maintainer (currently Leonard Zubkoff as he suggested this; he wrote me, In fact, the place we really need this is in the mid and upper levels, not so much in the drivers themselves. If the drivers return uniform results from the last resort error recovery functions, then the mid/upper levels can make sure the appropriate uniform HA-aware messages are emitted.).
Please keep in mind that the disks may also be a SPOF. You should either use RAID boxes or mirror the data using the MD driver. A setup that is definitely better than the previous one is shown below. It mirrors data across multiple disk adapters, disks and the associated cabling. Running software RAID across a single SCSI channel doesn't make very much sense, for performance and availability reasons.
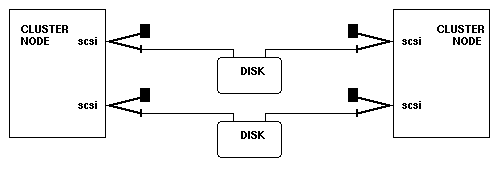
There are also some RAID boxes which have multiple SCSI connectors, e.g. the ones from Kingston Technology. Thus, Y cables are not needed. (Thanks to Chel van Gennip for this hint.)
One of the downsides of twintailing external SCSI disks (or disk boxes) to multiple nodes is that those nodes and the disks need to be attached to the same electrical power source, or more so to the same phase!
The reason is that the SCSI attachment is not potential free, and the devices share the same ground lines. For differential SCSI this doesn't harm as far as the data lines are concerned (up to a certain limit) but the termination power line (TERMPWR) is always asymmetrical and protected by a fuse.
Now if one of the devices/machines attached to the bus draws much more power from the power outlet, there will be a potential difference on the individual ground lines (due to the fact that the wire resistance is not equal to zero) which can be up to several volts. This will most probably blow the TERMPWR fuses on one or more of the termination power suppliers on the SCSI bus. This has been proven by practical experience in the past ...
The bottomline is, attach all the SCSI devices including the nodes to the same power outlet, as close as possible, to reduce GND potential shifts. BUT: this power outlet will be a SPOF which has to be protected by a UPS!
Serial Storage Architecture (SSA) is a high performance serial computer and peripheral interface that is being developed by X3T10.1, a Task Group of the X3T10 Technical Committee of Accredited Standards Committee X3. Initially developed by IBM, SSA is today an open technology promoted by the SSA Industry Association.
SSA is a serial technology which basically runs the SCSI-2 software protocol. This means device drivers for SSA adapters should be easily integrated into the existing Linux SCSI subsystem. The bottomline is, data is transferred via twisted-pair cables running at 200 MBit/s full-duplex which is a lot easier to handle than the 68-wire parallel Wide SCSI technology. For more information see the SSA Fact Sheet.
The good news about SSA compared to SCSI is:
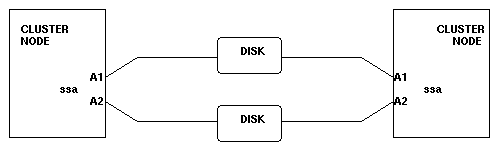
The simple example shown in the diagram can be enhanced by adding a second SSA adapter to each node, enabling this node to perform an intra-node adapter failover.
There are also some downsides of SSA:
There is no Linux SSA device driver today, however IBM Systems Storage Division (SSD) will support us to get one written for the IBM PCI SSA adapter -- and possibly officially endorse it, at least that is the usual process. There are at least two well-known SCSI device driver authors in the Linux community who are more than keen to write the device driver. I will get loan hardware and the device driver development toolkit in time. The loan contract will only be valid for 90 days, though, after which we will probably need to return the loan hardware. Donations are more than welcome!
I also contacted Pathlight Technology Inc.. Pathlight offers a single loop PCI SSA adapter which is simpler and probably cheaper than the IBM adapter. Pathlight is also going to support us but they currently have a problem with releasing the driver source code because it contains some parts which are considered confidential.
SSA documentation is available for free on the SSA Industry Association's Documentation and Standards page or from the Symbios Logic, Inc. anonymous FTP server.
A couple of prerequisites have to be fulfilled prior to getting the SSA device driver reasonably done. A major difference of SSA compared to external RAID boxes is that all disks are seen by the operating system individually. This currently limits us to 16 SCSI/SSA disks due to the major/minor device number scheme in the Linux kernel. (It appears the current development trend is to go for a 64 bit dev_t value which would allow us to use at least 16 bits for the minor device number.)
Remark: There is also a PCI SSA RAID adapter from IBM which does RAID levels 0 (striping), 1 (mirroring) and 5 (striping with parity) in hardware. The current adapter firmware doesn't support more than one adapter in a loop, however, which makes it unusable for multi-host attachments. This could change before too long. RAID 5 organized bunches of disks are presented to the operating system as single entities, and the adapter can group up to 14 plus 1 disks in a RAID 5 configuration. Since the biggest SSA disk is currently 9.1 GB, this sums up to 14 times 9.1 GB = 127.4 GB as a single entity. Please keep in mind that due to parity sum calculations which are needed for every write operation, mirrored setups (RAID level 1) are usually faster on writes than RAID level 5.
According to the SCSI development folks, the current Linux SCSI mid layer code is too slow to handle SSA data rates efficiently. This is a known problem which will hopefully be fixed as soon as there is a SSA device driver available.
Design Request: I herewith ask the Linux SCSI developers/maintainers to fix this as soon as possible, as well as re-design the disk and device numbering scheme to support more than 16 SCSI disks.
The SSA driver will also need to support SSA Target Mode (see section Non-IP Heartbeat).
Another way to attach SSA disks to a Linux machine is to use the so-called Serial Loop Interface Card (SLIC) built by Vicom Systems, Inc.. This device is also offered by IBM with the feature code #7190. The SLIC basically converts a F/W/D SCSI bus to a single SSA loop which can have up to 32 disks. The SLIC presents the disks to the operating system as 32 SCSI LUNs (logical units) on a single SCSI ID (remember we still have the 16 SCSI disks limitation inside Linux). The good news is that as long as the SLIC is the only SCSI target on the SCSI bus, there is no bus arbitration overhead. This results in a maximum sustained throughput of 18 MByte/s. The current SLIC supports only one SSA initiator per loop which is not good for a twin-tailed configuration but the requirement for multiple-initiator is recognized and will eventually be fulfilled. There will also be Ultra-SCSI versions which will sort of double the throughput.
Pathlight who was mentioned before is also going to release several SCSI-to-SSA converter tools. At NAB 97, they announced some interesting new products: a SSA 16 port hub is ready and in production, SSA Network Agent which interconnects SSA and Ultra Wide SCSI and Ethernet in one box and enables SCSI and SSA initiators and targets to transfer data between each other. Also they announced a new small black box called "Magic" that extends the SSA cable length to 100 meters (300 feet) on twisted pair copper cable.
Other disk technologies may be supported when they become available, e.g. Fibre Channel Arbitrated Loop (FC-AL), IEEE 1394 ("Firewire") etc.
Currently, all /dev/sd* and /dev/hd* devices are
buffered, i.e. writes are not committed instantly (although the
Linux kernel code suggests otherwise; in reality O_SYNC is there but
not implemented). Instead, reads and writes are
routed through the buffer cache. While this is probably nice for
filesystem performance, this is not good for storage ruggedness.
Several database products (e.g. Adabas D and Yard) could do better
with raw devices, having entire control of what's written on the
disk. I was also told that the port of Oracle for Linux was stopped
due to the fact that raw devices weren't there.
Plus, concurrent access is not possible at all with the
current buffered devices.
I appreciate any hint on any other database which could be accomodated by raw devices.
According to the SCSI development folks, raw devices will eventually be introduced during the SCSI mid layer code review.
We need to make sure disks are only accessed by the "active" node. There is no way to mount filesystems on multiple nodes at the same time since there is currently no locking mechanism. (If you need to concurrently access filesystems, I recommend to use a networked filesystem like NFS instead. NFS V2 is a bad performer, though.)
AIX has a mechanism called "varying on/off a volume group". Since we have no Logical Volume Manager yet in Linux (although there is a project in the works, see the Linux Virtual Partition System Project, see also here), there is no such mechanism. We can simulate the desired behaviour, though, if we load/unload the appropriate device driver modules during a takeover. There are two scenarios to this:
sd.o -- this is only
possible if the internal disks aren't SCSI but rather EIDE.
/proc/scsi/scsi interface
Module loading/unloading must not be done through kerneld because
Linux-HA needs to control disk access. We will use explicit
insmod/rmmod calls instead.
The same logic will apply to SSA as well.
The cluster manager daemon (or a subprocess) may run a "disk watchdog" which attempts to read/modify/write specific data blocks on the disks in short intervals to make sure they are still alive. This will also check the adapters, cables and bus termination (and an SSA SLIC if present) at a small performance penalty. This is only possible if there are raw disk devices, though, otherwise we'll always read the buffer cache instead of the disk.
SCSI disks are commonly reserved by an initiator by using the "SCSI Reserve" command. After a node failure, the Reserve Flag will still be set on the disks so that the takeover node will have to force a "break reservation". This feature isn't implemented in the SCSI code yet.
The third way of activating/deactivating disks via the
/proc/scsi/scsi interface could lead to the
situation where an integrating node has the disks
enabled first and needs to immediately deactivate
it. Plus, when handling a large number of disks, this
can become very difficult and error-prone. It allows
for having external and internal SCSI disks attached to
the same adapter type, though.
As long as there is support for just 16 SCSI disks, many users will go
for external RAID boxes. On the other hand, the standard solution in
the commercial AIX market is software mirroring on SSA disks. The
md (multiple devices) driver which is in the standard kernel
allows for mirroring, striping and concatenation on a partition
basis. RAID 5 is currently under development.
If the requirement for raw disk devices (see section
Raw Disk Devices) holds true, md also
has to provide for them.
The current quasi-standard Extended-2 filesystem (ext2) is pretty
stable and robust on a single machine. However in case of a node
failure, filesystems are not unmounted cleanly, causing time consuming
filesystem checks on the takeover node. Plus, it is not guaranteed
that an automatic filesystem check (fsck -a -A) detects and
repairs all errors encountered. Manual intervention may be needed.
This is completely and utterly unusable in a HA environment where customers expect a takeover node to be up and running within a couple of seconds or minutes without user intervention.
Thus, we need filesystems which work in a transaction-oriented manner: so-called log-structured filesystems. Currently, 4.5 potential solutions are identified:
The work on a transaction-oriented filesystem probably needs a major part of the work for Linux-HA. Developers are invited to join one of the projects to get it done sooner.
In the meantime, we have to live with the ext2 filesystem running on buffered block devices. Remember there is no real O_SYNC flag! We can't even really mount filesystems in synchronous mode.
When taking over filesystems, we need to make sure /etc/fstab
is in sync on all attached nodes. If the number of internal SCSI disks
is the same on all nodes (or if you only have internal EIDE disks),
the interesting portion of /etc/fstab simply needs to be
copied around. Otherwise we will have to adjust the entries for the
external disks accordingly. Alternatively, the configuration interface
may include a facility to configure/match disk partitions and
filesystems, and the disk takeover event scripts may explicitly mount the
filesystems according to the configuration database.
Since the partition table will be read off the disks we do not need to do
anything about synchronizing them across nodes. This is true even if
something was changed on the active node. Only if disk partitions /
filesystems are added, /etc/fstab has to be updated accordingly.
When performing a "clean" (i.e. manually controlled) failover, we
should run lsof to find and possibly close all files on the
external disks, as well as shut down all applications residing
there. This might not always work, for example if an application
has crashed and is in a zombie state. In this case, a disk may not be
cleanly released by the node leaving the cluster. For this reason, it
is highly recommended to not run any applications off the external
storage! Only the application's user data should be placed there.
You might consider mirroring the internal disks (and possibly the root partition as well) to make sure a machine doesn't fail when an internal disk fails. This is not trivial but will hopefully be documented in a mini-HOWTO. It was discussed on the linux-raid mailing list recently.
It is sometimes useful to cross-mount filesystems via NFS, for example
if data that is mounted on one cluster node must also be accessed on
other cluster nodes. Commercial HA software usually uses normal NFS
mounts but there is a downside to this. If the node which has the
disks mounted locally fails, the takeover node will have to unmount
the NFS mounts prior to locally mounting the disks (and taking over
the IP address, thus taking over the former NFS server's
functionality). Since the former NFS server is gone, umount fails, and
the umount process will have to wait for the RPC timeout, causing
long takeover times.
It is better to use the 4.4BSD automounter
amd instead. amd has two nice features which makes it suit
well into this scenario:
I was hinted towards the Coda Filesystem Project. It promises a fault-tolerant networked filesystem, and it looks as if it could be useful to replace NFS in a HA NFS server constallation.
The only devices for which SCSI is needed internally today are high
capacity tape devices such as DAT or Exabyte. If a client/server
backup solution is available, there is possibly no need for local tape
drives. Internal CDROM drives can be ATAPI, attached to one of the
EIDE channels on the mainboard. Internal disks can be EIDE as well,
and today there are EIDE disks with more than 6 GB capacity. Two such
disks, mirrored with md will provide for high capacity and
redundancy. The disks should be attached to different EIDE channels on
the mainboard for availability and performance reasons.